Das NADIKI Projekt stellt Forschenden eine JupyterLab-Umgebung bereit, die direkten Zugriff auf reale, pseudonymisierte Messdaten aus Produktivrechenzentren bietet. Über Jupyter Notebooks können Forschende Stromverbräuche, CPU-Auslastungen und Servereigenschaften abfragen, visualisieren und eigene Berechnungsmodelle entwickeln — ohne eigene Infrastruktur aufbauen zu müssen.
## Excerpt
Das NADIKI Projekt stellt Forschenden eine JupyterLab-Umgebung bereit, die direkten Zugriff auf reale, pseudonymisierte Messdaten aus Produktivrechenzentren bietet. Über Jupyter Notebooks können Forschende Stromverbräuche, CPU-Auslastungen und Servereigenschaften abfragen, visualisieren und eigene Berechnungsmodelle entwickeln — ohne eigene Infrastruktur aufbauen zu müssen.
## Content
Forschung zu Energieeffizienz und Umweltwirkung von Rechenzentren scheitert häufig an einem grundlegenden Problem: dem Zugang zu realen Daten. Betreiber geben Messdaten aus Vertraulichkeitsgründen selten heraus, und öffentlich verfügbare Datensätze bilden die Komplexität realer Produktivsysteme kaum ab. Mit dem NADIKI Projekt schließen wir diese Lücke — über eine JupyterLab-Umgebung, die Forschenden direkten Zugriff auf pseudonymisierte Messdaten aus vier Pilotrechenzentren gibt.
Was ist JupyterLab?
JupyterLab ist eine browserbasierte Entwicklungsumgebung für interaktive Datenanalyse. Kernstück sind Jupyter Notebooks: Dokumente, die ausführbaren Code (Python, R, Julia), Visualisierungen und erklärenden Text in einer Oberfläche vereinen. Forschende schreiben eine Abfrage, führen sie aus und sehen das Ergebnis unmittelbar — als Tabelle, Diagramm oder statistische Auswertung. Dieser iterative Workflow macht JupyterLab zum Standard-Werkzeug in der Datenforschung: Hypothesen lassen sich schnell überprüfen, Berechnungsmodelle schrittweise entwickeln und Ergebnisse reproduzierbar dokumentieren.
Im NADIKI Projekt ist JupyterLab direkt an die Datenbanken des Registrar-Systems angebunden. Forschende greifen auf InfluxDB (Zeitreihendaten wie Stromverbrauch und Auslastung) und indirekt auf eine MariaDB über die Registrar-API (statische Systemeigenschaften wie Hardware-Konfigurationen und Standortdaten) zu — ohne eigene Infrastruktur betreiben zu müssen.
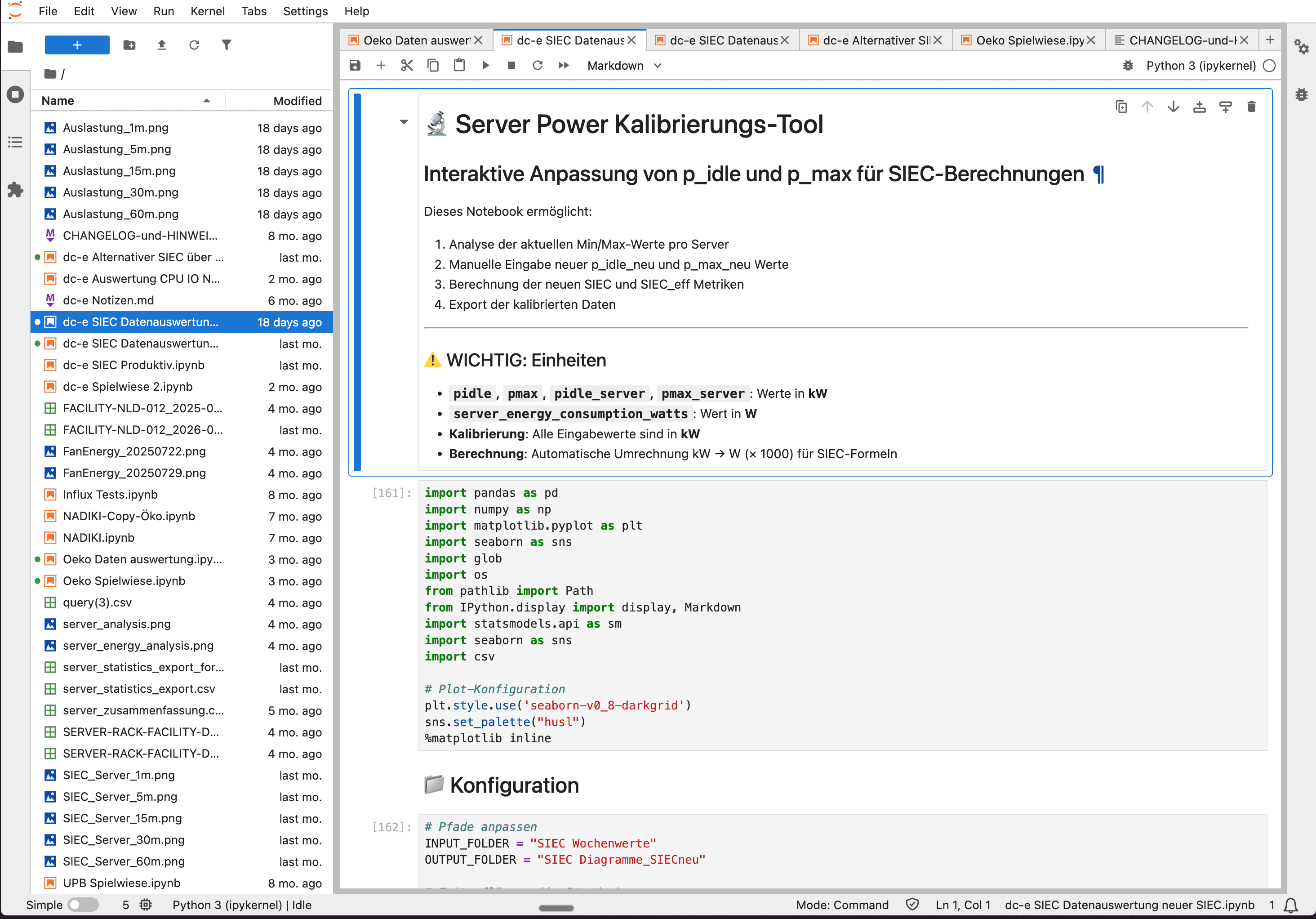
Welche Daten stehen zur Verfügung?
Die Forschungsumgebung bietet Zugang zu zwei Datenkategorien aus den angeschlossenen Pilotrechenzentren:
Statische Systemeigenschaften: Rechenzentrumsdaten wie PUE, Fläche, USV-Status und Dieselgenerator-Eigenschaften. Auf Server-Ebene: CPU-Modelle, GPU-Konfigurationen, Speicherkapazität und RAM-Ausstattung. Diese Daten stammen aus der Registrierung der Assets im Observer-System.
Dynamische Metriken: Zeitreihen zu Stromverbrauch, CPU-Auslastung, Kühlleistung, Netzwerkverkehr sowie Schreib- und Lesevorgängen. Diese Daten fließen kontinuierlich von den Pilotrechenzentren in die InfluxDB des Registrars.
Alle Daten sind pseudonymisiert: Standorte, Betreiber und Asset-Kennungen sind anonymisiert, die Messreihen und Systemeigenschaften bleiben vollständig erhalten.
> Quelle: IDED JupyterLab Forschungsumgebung
Was Forschende damit machen können
Die Notebooks, die wir bereitstellen, zeigen exemplarische Analysen — Forschende können sie als Ausgangspunkt nutzen und eigene Fragestellungen entwickeln:
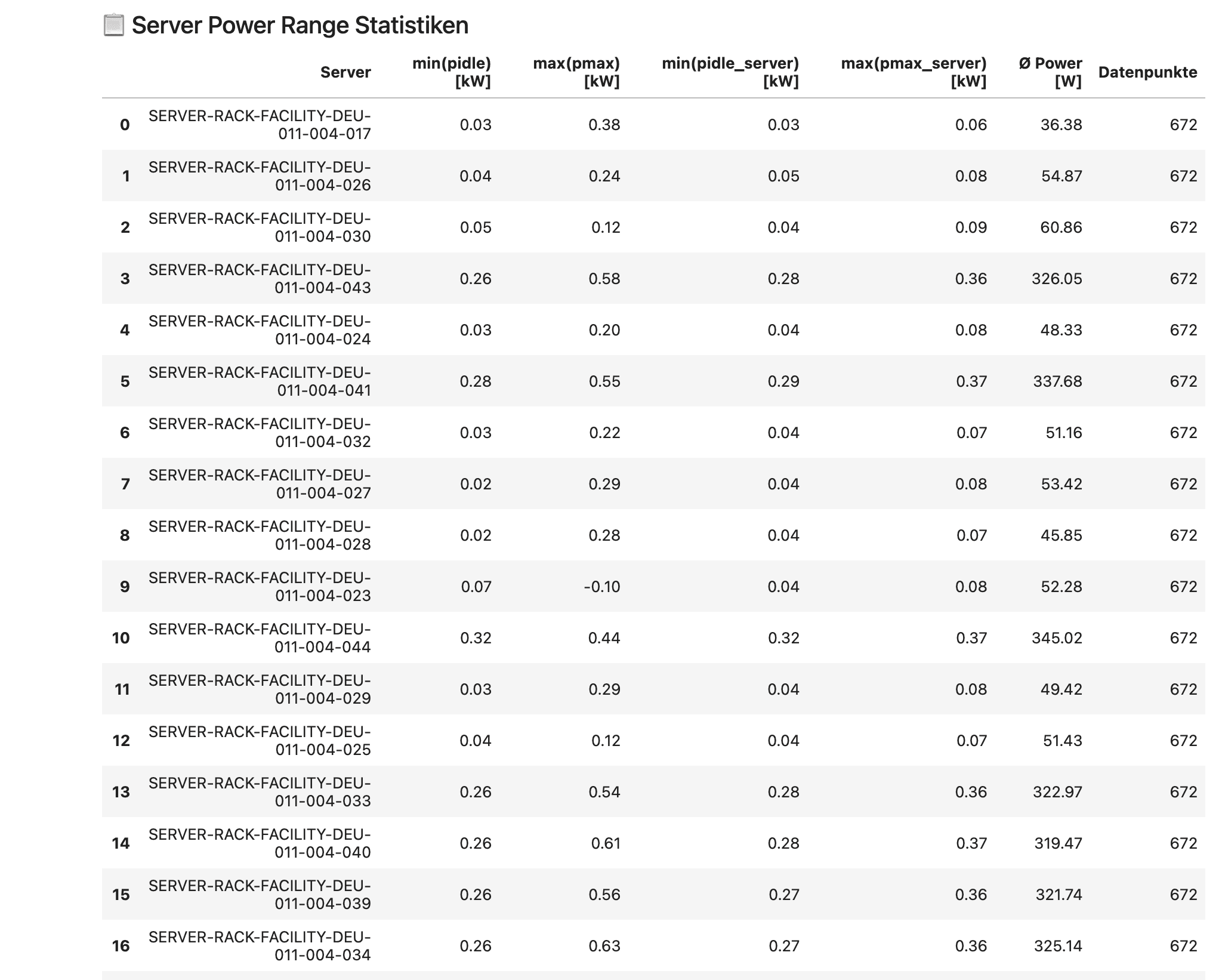
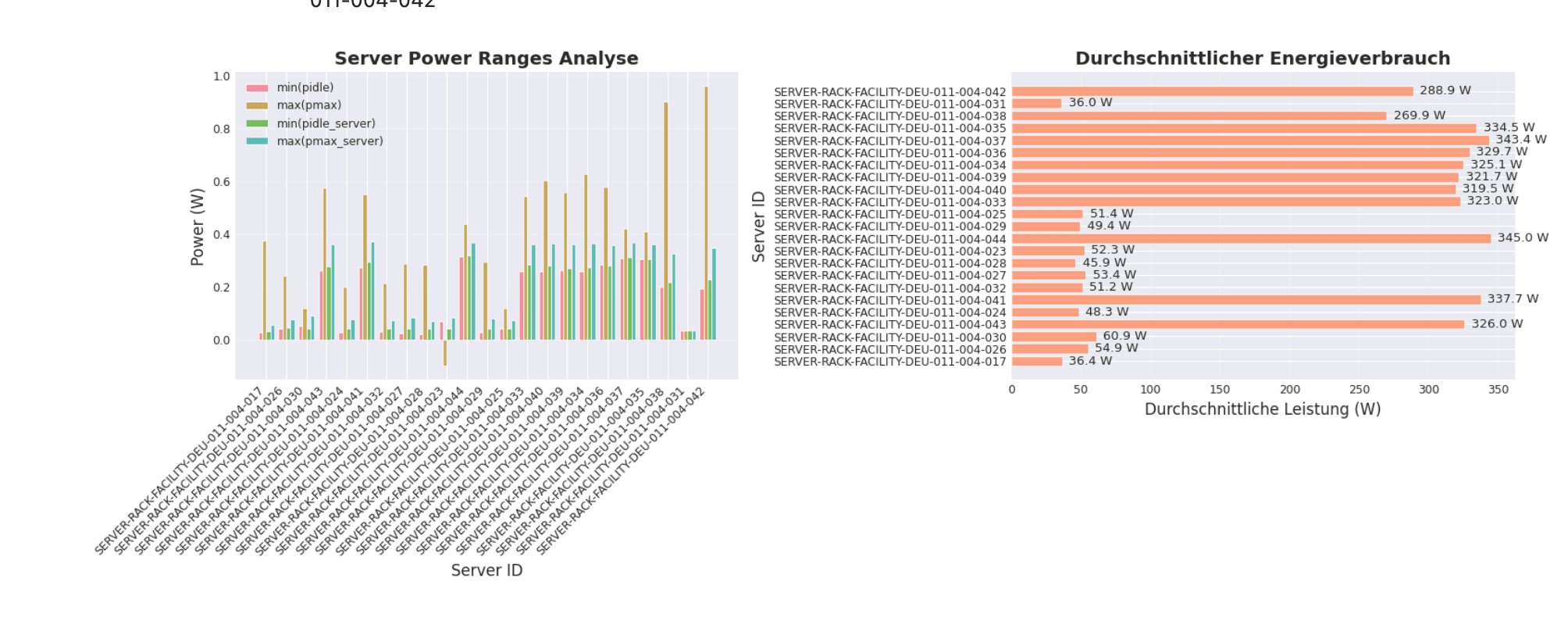
Energieverbrauchsanalyse: Stromverbräuche einzelner Server über Zeiträume auswerten, Idle-Verbräuche identifizieren und Lastprofile vergleichen. Die Power-Range-Statistiken zeigen für jeden Server die minimale und maximale Leistungsaufnahme im Idle- und Lastbetrieb.
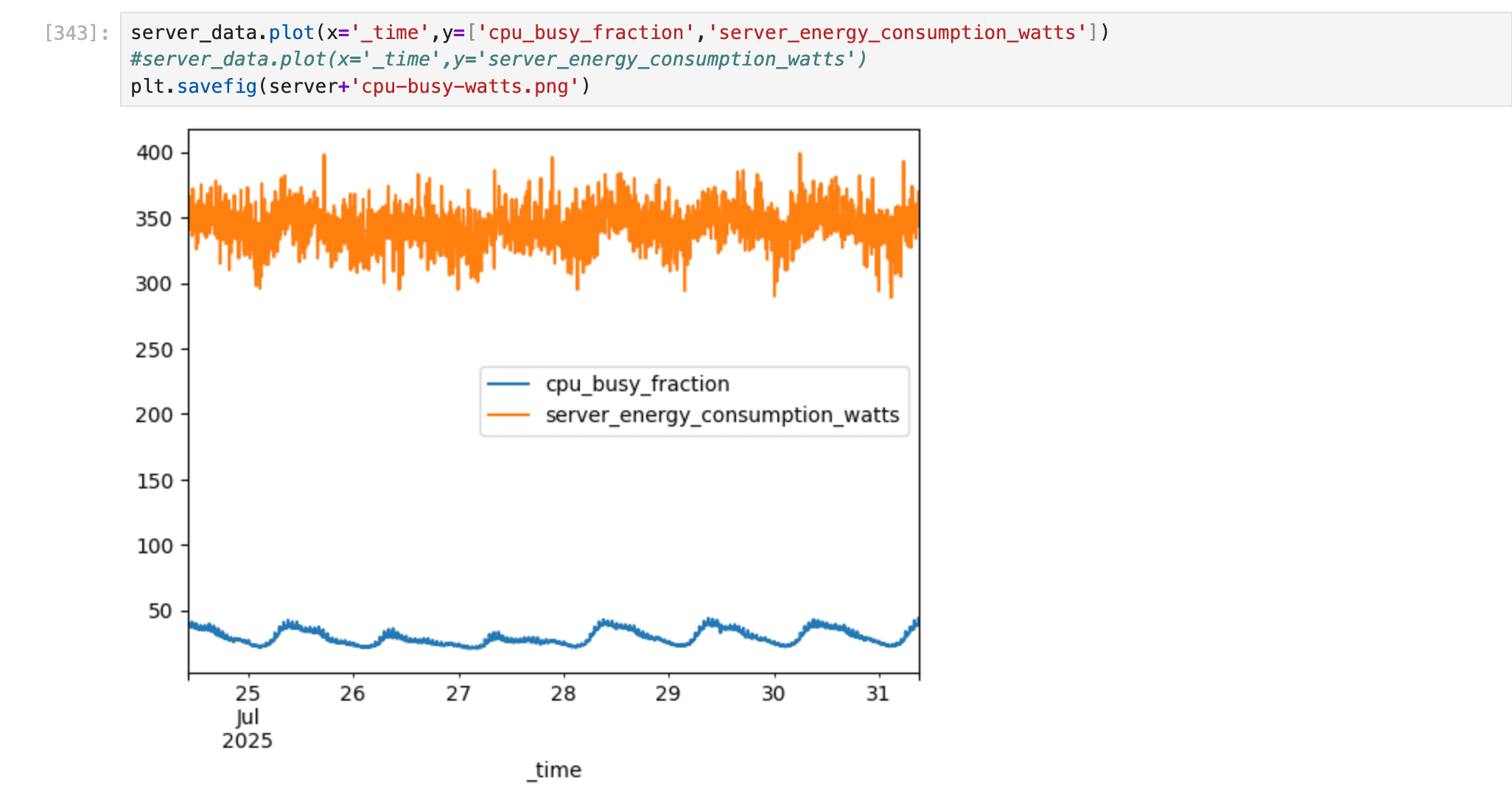
Effizienzkorrelationen: Zusammenhänge zwischen CPU-Auslastung und Stromverbrauch untersuchen — etwa um zu analysieren, wie sich Laständerungen auf den Energiebedarf auswirken.
Umweltwirkungsmodelle: Neue Berechnungsmodelle für die Umweltwirkungszurechnung prototypisch testen — etwa alternative Allokationsverfahren oder verfeinerte Interpolationsmethoden für fehlende Messwerte.
Kalibrierung: Server-Power-Modelle anhand realer Messdaten kalibrieren, um die Genauigkeit von Energieverbrauchsschätzungen zu verbessern.
> Quelle: IDED JupyterLab Forschungsumgebung
> Quelle: IDED JupyterLab Forschungsumgebung
Zugang anfragen
Forschende können Zugang zur JupyterLab-Umgebung über das Antragsformular anfragen.